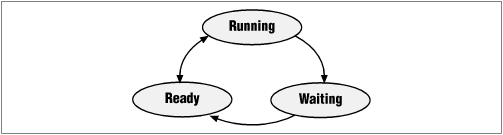
Figure 8-1. Possible states of a task
osophobia n. A common fear among embedded systems programmers.
All but the most trivial of embedded programs will benefit from the inclusion of an operating system. This can range from a small kernel written by you to a full-featured commercial operating system. Either way, you'll need to know what features are the most important and how their implementation will affect the rest of your software. At the very least, you need to understand what an embedded operating system looks like on the outside. But there's probably no better way to understand the exterior interfaces than to examine a small operating system in its entirety. So that's what we'll do in this chapter.
In the early days of computing there was no such thing as an operating system. Application programmers were completely responsible for controlling and monitoring the state of the processor and other hardware. In fact, the purpose of the first operating systems was to provide a virtual hardware platform that made application programs easier to write. To accomplish this goal, operating system developers needed only provide a loose collection of routines—much like a modern software library—for resetting the hardware to a known state, reading the state of the inputs, and changing the state of the outputs.
Modern operating systems add to this the ability to execute multiple software tasks simultaneously on a single processor. Each such task is a piece of the software that can be separated from and run independently of the rest. A set of embedded software requirements can usually be decomposed into a small number of such independent pieces. For example, the printer-sharing device described in Chapter 5, contains three obvious software tasks:
Task 1: Receive data from the computer attached to serial port A.
Task 2: Receive data from the computer attached to serial port B.
Task 3: Format and send the waiting data (if any) to the printer attached to the parallel port.
Tasks provide a key software abstraction that makes the design and implementation of embedded software easier and the resulting source code simpler to understand and maintain. By breaking the larger program up into smaller pieces, the programmer can more easily concentrate her energy and talents on the unique features of the system under development.
Strictly speaking, an operating system is not a required component of any computer system—embedded or otherwise. It is always possible to perform the same functions from within the application program itself. Indeed, all of the examples so far in this book have done just that. There is simply one path of execution—starting at main —that is downloaded into the system and run. This is the equivalent of having only one task. But as the complexity of the application expands beyond just blinking an LED, the benefits of an operating system far outweigh the associated costs.
If you have never worked on operating system internals before, you might have the impression that they are complex. I'm sure the operating system vendors would like you to continue to believe that they are and that only a handful of computer scientists are capable of writing one. But I'm here to let the cat out of the bag: it's not all that hard! In fact, embedded operating systems are even easier to write than their desktop cousins—the required functionality is smaller and better defined. Once you learn what that functionality is and a few implementation techniques, you will see that an operating system is no harder to develop than any other piece of embedded software.
Embedded operating systems are small because they lack many of the things you would expect to find on your desktop computer. For example, embedded systems rarely have disk drives or graphical displays, and hence they need no filesystem or graphical user interface in their operating systems. In addition, there is only one "user" (i.e., all of the tasks that comprise the embedded software cooperate), so the security features of multiuser operating systems do not apply. All of these are features that could be part of an embedded operating system but are unnecessary in the majority of cases.
What follows is a description of an embedded operating system that I have developed on my own. I call my operating system ADEOS (pronounced the same as the Spanish farewell), which is an acronym for "A Decent Embedded Operating System." I think that name really sums it up nicely. Yes, it is an embedded operating system; but it is neither the best nor the worst in any regard. In all, there are less than 1000 lines of source code. Of these, three quarters are platform-independent and written in C++. The rest are hardware- or processor-specific and, therefore, written in assembly language. In the discussion later, I will present and explain all of the routines that are written in C++ along with the theory you need to understand them. In the interest of clarity, I will not present the source code for the assembly language routines. Instead, I will simply state their purpose and assume that interested readers will download and examine that code on their own.
If you would like to use ADEOS (or a modified version of it) in your embedded system, please feel free to do so. In fact, I would very much like to hear from anyone who uses it. I have made every effort to test the code and improve upon the weaknesses I have uncovered. However, I can make no guarantee that the code presented in this chapter is useful for any purpose other than learning about operating systems. If you decide to use it anyway, please be prepared to spend some amount of your time finding and fixing bugs in the operating system itself.
We have already talked about multitasking and the idea that an operating system makes it possible to execute multiple "programs" at the same time. But what does that mean? How is it possible to execute several tasks concurrently? In actuality, the tasks are not executed at the same time. Rather, they are executed in pseudoparallel. They merely take turns using the processor. This is similar to the way several people might read the same copy of a book. Only one person can actually use the book at a given moment, but they can both read it by taking turns using it.
An operating system is responsible for deciding which task gets to use the processor at a particular moment. In addition, it maintains information about the state of each task. This information is called the task's context, and it serves a purpose similar to a bookmark. In the multiple book reader scenario, each reader is presumed to have her own bookmark. The bookmark's owner must be able to recognize it (e.g., it has her name written on it), and it must indicate where she stopped reading when last she gave up control of the book. This is the reader's context.
A task's context records the state of the processor just prior to another task's taking control of it. This usually consists of a pointer to the next instruction to be executed (the instruction pointer), the address of the current top of the stack (the stack pointer), and the contents of the processor's flag and general-purpose registers. On 16-bit 80x86 processors, these are the registers CS and IP, SS and SP, Flags, and DS, ES, SI, DI, AX, BX, CX, and DX, respectively.
In order to keep tasks and their contexts organized, the operating system maintains a bit of information about each task. Operating systems written in C often keep this information in a data structure called the task control block. However, ADEOS is written in C++ and one of the advantages of this approach is that the task-specific data is automatically made a part of the task object itself. The definition of a Task, which includes the information that the operating system needs, is as follows:
class Task
{
public:
Task(void (*function)(), Priority p, int stackSize);
TaskId id;
Context context;
TaskState state;
Priority priority;
int * pStack;
Task * pNext;
void (*entryPoint)();
private:
static TaskId nextId;
};
Many of the data members of this class will make sense only after we discuss the operating system in greater detail. However, the first two fields—id and context--should already sound familiar. The id contains a unique integer (between and 255) that identifies the task. In other words, it is the name on the bookmark. The context is the processor-specific data structure that actually contains the state of the processor the last time this task gave up control of the processor.
Remember how I said that only one task could actually be using the processor at a given time? That task is said to be the " running" task, and no other task can be in that same state at the same time. Tasks that are ready to run—but are not currently using the processor—are in the "ready" state, and tasks that are waiting for some event external to themselves to occur before going on are in the "waiting" state. Figure 8-1 shows the relationships between these three states.
A transition between the ready and running states occurs whenever the operating system selects a new task to run. The task that was previously running becomes ready, and the new task (selected from the pool of tasks in the ready state) is promoted to running. Once it is running, a task will leave that state only if it is forced to do so by the operating system or if it needs to wait for some event external to itself to occur before continuing. In the latter case, the task is said to block, or wait, until that event occurs. And when that happens, the task enters the waiting state and the operating system selects one of the ready tasks to be run. So, although there may be any number of tasks in each of the ready and waiting states, there will never be more (or less) than one task in the running state at any time.
Here's how a task's state is actually defined in ADEOS:
enum TaskState { Ready, Running, Waiting };
It is important to note that only the scheduler—the part of the operating system that decides which task to run—can promote a task to the running state. Newly created tasks and tasks that are finished waiting for their external event are placed into the ready state first. The scheduler will then include these new ready tasks in its future decision-making.
As an application developer working with ADEOS (or any other operating system), you will need to know how to create and use tasks. Like any other abstract data type, the Task class has its own set of routines to do just that. However, the task interface in ADEOS is simpler than most because you can do nothing but create new Task objects. Once created, an ADEOS task will continue to exist in the system until the associated function returns. Of course, that might not happen at all, but if it does, the task will be deleted automatically by the operating system.
The Task constructor is shown below. The caller assigns a function, a priority, and an optional stack size to the new task by way of the constructor's parameters. The first parameter, function, is a pointer to the C/C++ or assembly language function that is to be executed within the context of the new task. The only requirements for this function are that it take no arguments and return nothing. The second parameter, p, is a unique number from 1 to 255 that represents the new task's priority relative to other tasks in the system. These numbers are used by the scheduler when it is selecting the next task to be run (higher numbers represent higher priorities).
TaskId Task::nextId = 0;
/**********************************************************************
*
* Method: Task()
*
* Description: Create a new task and initialize its state.
*
* Notes:
*
* Returns:
*
**********************************************************************/
Task::Task(void (*function)(), Priority p, int stackSize)
{
stackSize /= sizeof(int); // Convert bytes to words.
enterCS(); ////// Critical Section Begin
//
// Initialize the task-specific data.
//
id = Task::nextId++;
state = Ready;
priority = p;
entryPoint = function;
pStack = new int[stackSize];
pNext = NULL;
//
// Initialize the processor context.
//
contextInit(&context, run, this, pStack + stackSize);
//
// Insert the task into the ready list.
//
os.readyList.insert(this);
os.schedule(); // Scheduling Point
exitCS(); ////// Critical Section End
} /* Task() */
Notice how the functional part of this routine is surrounded by the two function calls enterCS and exitCS. The block of code between these calls is said to be a critical section. A critical section is a part of a program that must be executed atomically. That is, the instructions that make up that part must be executed in order and without interruption. Because an interrupt can occur at any time, the only way to make such a guarantee is to disable interrupts for the duration of the critical section. So enterCS is called at the beginning of the critical section to save the interrupt enable state and disable further interrupts. And exitCS is called at the end to restore the previously saved interrupt state. We will see this same technique used in each of the routines that follow.
There are several other routines that I've called from the constructor in the previous code, but I don't have the space to list here. These are the routines contextInit and os.readyList.insert. The contextInit routine establishes the initial context for a task. This routine is necessarily processor-specific and, therefore, written in assembly language.
contextInit has four parameters. The first is a pointer to the context data structure that is to be initialized. The second is a pointer to the startup function. This is a special ADEOS function, called run, that is used to start a task and clean up behind it if the associated function later exits. The third parameter is a pointer to the new Task object. This parameter is passed to run so the function associated with the task can be started. The fourth and final parameter is a pointer to the new task's stack.
The other function call is to os.readyList.insert. This call adds the new task to the operating system's internal list of ready tasks. The readyList is an object of type TaskList. This class is just a linked list of tasks (ordered by priority) that has two methods: insert and remove. Interested readers should download and examine the source code for ADEOS if they want to see the actual implementation of these functions. You'll also learn more about the ready list in the discussion that follows.
Application Programming InterfacesOne of the most annoying things about embedded operating systems is their lack of a common API. This is a particular problem for companies that want to share application code between products that are based on different operating systems. One company I worked for even went so far as to create their own layer above the operating system solely to isolate their application programmers from these differences. But surely this was just adding to the overall problem—by creating yet another API. The basic functionality of every embedded operating system is much the same. Each function or method represents a service that the operating system can perform for the application program. But there aren't that many different services possible. And it is frequently the case that the only real difference between two implementations is the name of the function or method. This problem has persisted for several decades, and there is no end in sight. Yet during that same time the Win32 and POSIX APIs have taken hold on PCs and Unix workstations, respectively. So why hasn't a similar standard emerged for embedded systems? It hasn't been for a lack of trying. In fact, the authors of the original POSIX standard (IEEE 1003.1) also created a standard for real-time systems (IEEE 1003.4b). And a few of the more Unix-like embedded operating systems (VxWorks and LynxOS come to mind) are compliant with this standard API. However, for the vast majority of application programmers, it is necessary to learn a new API for each operating system used. Fortunately, there is a glimmer of hope. The Java programming language has support for multitasking and task synchronization built in. That means that no matter what operating system a Java program is running on, the mechanics of creating and manipulating tasks and synchronizing their activities remain the same. For this and several other reasons, Java would be a very nice language for embedded programmers. I hope that there will some day be a need for a book about embedded systems programming in Java and that a sidebar like this one will, therefore, no longer be required. |
The heart and soul of any operating system is its scheduler. This is the piece of the operating system that decides which of the ready tasks has the right to use the processor at a given time. If you've written software for a mainstream operating system, then you might be familiar with some of the more common scheduling algorithms: first-in-first-out, shortest job first, and round robin. These are simple scheduling algorithms that are used in nonembedded systems.
First-in-first-out (FIFO) scheduling describes an operating system like DOS, which is not a multitasking operating system at all. Rather, each task runs until it is finished, and only after that is the next task started. However, in DOS a task can suspend itself, thus freeing up the processor for the next task. And that's precisely how older version of the Windows operating system permitted users to switch from one task to another. True multitasking wasn't a part of any Microsoft operating system before Windows NT.
Shortest job first describes a similar scheduling algorithm. The only difference is that each time the running task completes or suspends itself, the next task selected is the one that will require the least amount of processor time to complete. Shortest job first was common on early mainframe systems because it has the appealing property of maximizing the number of satisfied customers. (Only the customers who have the longest jobs tend to notice or complain.)
Round robin is the only scheduling algorithm of the three in which the running task can be preempted, that is, interrupted while it is running. In this case, each task runs for some predetermined amount of time. After that time interval has elapsed, the running task is preempted by the operating system and the next task in line gets its chance to run. The preempted task doesn't get to run again until all of the other tasks have had their chances in that round.
Unfortunately, embedded operating systems cannot use any of these simplistic scheduling algorithms. Embedded systems (particularly real-time systems) almost always require a way to share the processor that allows the most important tasks to grab control of the processor as soon as they need it. Therefore, most embedded operating systems utilize a priority-based scheduling algorithm that supports preemption. This is a fancy way of saying that at any given moment the task that is currently using the processor is guaranteed to be the highest-priority task that is ready to do so. Lower-priority tasks must wait until higher-priority tasks are finished using the processor before resuming their work. The word preemptive adds that any running task can be interrupted by the operating system if a task of higher priority becomes ready. The scheduler detects such conditions at a finite set of time instants called scheduling points.
When a priority-based scheduling algorithm is used, it is also necessary to have a backup policy. This is the scheduling algorithm to be used in the event that several ready tasks have the same priority. The most common backup scheduling algorithm is round robin. However, for simplicity's sake, I've implemented only a FIFO scheduler for my backup policy. For that reason, users of ADEOS should take care to assign a unique priority to each task whenever possible. This shouldn't be a problem though, because ADEOS supports as many priority levels as tasks (up to 255 of each).
The scheduler in ADEOS is implemented in a class called Sched:
class Sched
{
public:
Sched();
void start();
void schedule();
void enterIsr();
void exitIsr();
static Task * pRunningTask;
static TaskList readyList;
enum SchedState { Uninitialized, Initialized, Started };
private:
static SchedState state;
static Task idleTask;
static int interruptLevel;
static int bSchedule;
};
After defining this class, an object of this type is instantiated within one of the operating system modules. That way, users of ADEOS need only link the file sched.obj to include an instance of the scheduler. This instance is called os and is declared as follows:
extern Sched os;
References to this global variable can be made from within any part of the application program. But you'll soon see that only one such reference will be necessary per application.
Simply stated, the scheduling points are the set of operating system events that result in an invocation of the scheduler. We have already encountered two such events: task creation and task deletion. During each of these events, the method os.schedule is called to select the next task to be run. If the currently executing task still has the highest priority of all the ready tasks, it will be allowed to continue using the processor. Otherwise, the highest priority ready task will be executed next. Of course, in the case of task deletion a new task is always selected: the currently running task is no longer ready, by virtue of the fact that it no longer exists!
A third scheduling point is called the clock tick. The clock tick is a periodic event that is triggered by a timer interrupt. The clock tick provides an opportunity to awake tasks that are waiting for a software timer to expire. This is almost exactly the same as the timer tick we saw in the previous chapter. In fact, support for software timers is a common feature of embedded operating systems. During the clock tick, the operating system decrements and checks each of the active software timers. When a timer expires, all of the tasks that are waiting for it to complete are changed from the waiting state to the ready state. Then the scheduler is invoked to see if one of these newly awakened tasks has a higher priority than the task that was running prior to the timer interrupt.
The clock tick routine in ADEOS is almost exactly the same as the one in Chapter 7. In fact, we still use the same Timer class. Only the implementation of this class has been changed, and that only slightly. These changes are meant to account for the fact that multiple tasks might be waiting for the same software timer. In addition, all of the calls to disable and enable have been replaced by enterCS and exitCS, and the length of a clock tick has been increased from 1 ms to 10 ms.
The scheduler uses a data structure called the ready list to track the tasks that are in the ready state. In ADEOS, the ready list is implemented as an ordinary linked list, ordered by priority. So the head of this list is always the highest priority task that is ready to run. Following a call to the scheduler, this will be the same as the currently running task. In fact, the only time that won't be the case is during a reschedule. Figure 8-2 shows what the ready list might look like while the operating system is in use.
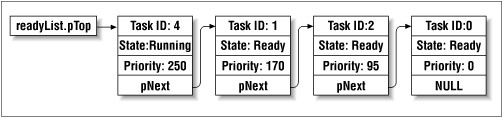
The main advantage of an ordered linked list like this one is the ease with which the scheduler can select the next task to be run. (It's always at the top.) Unfortunately, there is a tradeoff between lookup time and insertion time. The lookup time is minimized because the data member readyList always points directly to the highest priority ready task. However, each time a new task changes to the ready state, the code within the insert method must walk down the ready list until it finds a task that has a lower priority than the one being inserted. The newly ready task is inserted in front of that task. As a result, the insertion time is proportional to the average number of tasks in the ready list.
If there are no tasks in the ready state when the scheduler is called, the idle task will be executed. The idle task looks the same in every operating system. It is simply an infinite loop that does nothing. In ADEOS, the idle task is completely hidden from the application developer. It does, however, have a valid task ID and priority (both of which are zero, by the way). The idle task is always considered to be in the ready state (when it is not running), and because of its low priority, it will always be found at the end of the ready list. That way, the scheduler will find it automatically when there are no other tasks in the ready state. Those other tasks are sometimes referred to as user tasks to distinguish them from the idle task.
Because I use an ordered linked list to maintain the ready list, the scheduler is easy to implement. It simply checks to see if the running task and the highest-priority ready task are one and the same. If they are, the scheduler's job is done. Otherwise, it will initiate a context switch from the former task to the latter. Here's what this looks like when it's implemented in C++:
/**********************************************************************
*
* Method: schedule()
*
* Description: Select a new task to be run.
*
* Notes: If this routine is called from within an ISR, the
* schedule will be postponed until the nesting level
* returns to zero.
*
* The caller is responsible for disabling interrupts.
*
* Returns: None defined.
*
**********************************************************************/
void
Sched::schedule(void)
{
Task * pOldTask;
Task * pNewTask;
if (state != Started) return;
//
// Postpone rescheduling until all interrupts are completed.
//
if (interruptLevel != 0)
{
bSchedule = 1;
return;
}
//
// If there is a higher-priority ready task, switch to it.
//
if (pRunningTask != readyList.pTop)
{
pOldTask = pRunningTask;
pNewTask = readyList.pTop;
pNewTask->state = Running;
pRunningTask = pNewTask;
if (pOldTask == NULL)
{
contextSwitch(NULL, &pNewTask->context);
}
else
{
pOldTask->state = Ready;
contextSwitch(&pOldTask->context, &pNewTask->context);
}
}
} /* schedule() */
As you can see from this code, there are two situations during which the scheduler will not initiate a context switch. The first is if multitasking has not been enabled. This is necessary because application programmers sometimes want to create some or all of their tasks before actually starting the scheduler. In that case, the application's main routine would look like the following one. Each time a Task object is created, the scheduler is invoked.[1]
However, because schedule checks the value of state to ensure that multitasking has been started, no context switches will occur until after start is called.
#include "adeos.h"
void taskAfunction(void);
void taskBfunction(void);
/*
* Create two tasks, each with its own unique function and priority.
*/
Task taskA(taskAfunction, 150, 256);
Task taskB(taskBfunction, 200, 256);
/*********************************************************************
*
* Function: main()
*
* Description: This is what an application program might look like
* if ADEOS were used as the operating system. This
* function is responsible for starting the operating
* system only.
*
* Notes: Any code placed after the call to os.start() will
* never be executed. This is because main() is not a
* task, so it does not get a chance to run once the
* scheduler is started.
*
* Returns: This function will never return!
*
*********************************************************************/
void
main(void)
{
os.start();
// This point will never be reached.
} /* main() */
Because this is an important piece of code, let me reiterate what you are looking at. This is an example of the application code you might write as a user of ADEOS. You begin by including the header file adeos.h and declaring your tasks. After you declare the tasks and call os.start, the task functions taskAfunction and taskBfunction will begin to execute (in pseudoparallel). Of course, taskB has the highest priority of the two (200), so it will get to run first. However, as soon as it relinquishes control of the processor for any reason, the other task will have a chance to run as well.
The other situation in which the ADEOS scheduler will not perform a context switch is during interrupt processing. The operating system tracks the nesting level of the current interrupt service routine and allows context switches only if the nesting level is zero. If the scheduler is called from an ISR (as it is during the timer tick), the bSchedule flag is set to indicate that the scheduler should be called again as soon as the outermost interrupt handler exits. This delayed scheduling speeds up interrupt response times throughout the system.
The actual process of changing from one task to another is called a context switch. Because contexts are processor-specific, so is the code that implements the context switch. That means it must always be written in assembly language. Rather than show you the 80x86-specific assembly code that I used in ADEOS, I'll show the context switch routine in a C-like pseudocode:
void
contextSwitch(PContext pOldContext, PContext pNewContext)
{
if (saveContext(pOldContext))
{
//
// Restore new context only on a nonzero exit from saveContext().
//
restoreContext(pNewContext);
// This line is never executed!
}
// Instead, the restored task continues to execute at this point.
}
The contextSwitch routine is actually invoked by the scheduler, which is in turn called from one of the operating system calls that disables interrupts. So it is not necessary to disable interrupts here. In addition, because the operating system call that invoked the scheduler is written in a high-level language, most of the running task's registers have already been saved onto its local stack. That reduces the amount of work that needs to be done by the routines saveContext and restoreContext. They need only worry about saving the instruction pointer, stack pointer, and flags.
The actual behavior of contextSwitch at runtime is difficult to see simply by looking at the previous code. Most software developers think serially, assuming that each line of code will be executed immediately following the previous one. However, this code is actually executed two times, in pseudoparallel. When one task (the new task) changes to the running state, another (the old task) must simultaneously go back to the ready state. Imagine what the new task sees when it is restored inside the restoreContext code. No matter what the new task was doing before, it always wakes up inside the saveContext code—because that's where its instruction pointer was saved.
How does the new task know whether it is coming out of saveContext for the first time (i.e., in the process of going to sleep) or the second time (in the process of waking up)? It definitely does need to know the difference, so I've had to implement saveContext in a slightly sneaky way. Rather than saving the precise current instruction pointer, saveContext actually saves an address a few instructions ahead. That way, when the saved context is restored, execution continues from a different point in the saveContext routine. This also makes it possible for saveContext to return different values: nonzero when the task goes to sleep and zero when the task wakes up. The contextSwitch routine uses this return value to decide whether to call restoreContext. If contextSwitch did not perform this check, the code associated with the new task would never get to execute.
I know this can be a complicated sequence of events to follow, so I've illustrated the whole process in Figure 8-3.

Though we frequently talk about the tasks in a multitasking operating system as completely independent entities, that portrayal is not completely accurate. All of the tasks are working together to solve a larger problem and must occasionally communicate with one another to synchronize their activities. For example, in the printer-sharing device the printer task doesn't have any work to do until new data is supplied to it by one of the computer tasks. So the printer and computer tasks must communicate with one another to coordinate their access to common data buffers. One way to do this is to use a data structure called a mutex.
Mutexes are provided by many operating systems to assist with task synchronization. They are not, however, the only such mechanism available. Others are called semaphores, message queues, and monitors. However, if you have any one of these data structures, it is possible to implement each of the others. In fact, a mutex is itself a special type of semaphore called a binary, or mutual-exclusion, semaphore.
You can think of a mutex as being nothing more than a multitasking-aware binary flag. The meaning associated with a particular mutex must, therefore, be chosen by the software designer and understood by each of the tasks that use it. For example, the data buffer that is shared by the printer and computer task would probably have a mutex associated with it. When this binary flag is set, the shared data buffer is assumed to be in use by one of the tasks. All other tasks must wait until that flag is cleared (and then set again by themselves) before reading or writing any of the data within that buffer.
We say that mutexes are multitasking-aware because the processes of setting and clearing the binary flag are atomic. That is, these operations cannot be interrupted. A task can safely change the state of the mutex without risking that a context switch will occur in the middle of the modification. If a context switch were to occur, the binary flag might be left in an unpredictable state and a deadlock between the tasks could result. The atomicity of the mutex set and clear operations is enforced by the operating system, which disables interrupts before reading or modifying the state of the binary flag.
ADEOS includes a Mutex class. Using this class, the application software can create and destroy mutexes, wait for a mutex to be cleared and then set it, or clear a mutex that was previously set. The last two operations are referred to as taking and releasing a mutex, respectively.
Here is the definition of the Mutex class:
class Mutex
{
public:
Mutex();
void take(void);
void release(void);
private:
TaskList waitingList;
enum { Available, Held } state;
};
The process of creating a new Mutex is simple. The following constructor will be executed automatically each time a new mutex object is instantiated:
/**********************************************************************
*
* Method: Mutex()
*
* Description: Create a new mutex.
*
* Notes:
*
* Returns:
*
**********************************************************************/
Mutex::Mutex()
{
enterCS(); ////// Critical Section Begin
state = Available;
waitingList.pTop = NULL;
exitCS(); ////// Critical Section End
} /* Mutex() */
All mutexes are created in the Available state and are associated with a linked list of waiting tasks that is initially empty. Of course, once you've created a mutex it is necessary to have some way to change its state, so the next method we'll discuss is take. This routine would typically be called by a task, before it reads or writes a shared resource. When the call to take returns, the calling task's exclusive access to that resource is guaranteed by the operating system. The code for this routine is as follows:
/**********************************************************************
*
* Method: take()
*
* Description: Wait for a mutex to become available, then take it.
*
* Notes:
*
* Returns: None defined.
*
**********************************************************************/
void
Mutex::take(void)
{
Task * pCallingTask;
enterCS(); ////// Critical Section Begin
if (state == Available)
{
//
// The mutex is available. Simply take it and return.
//
state = Held;
waitingList.pTop = NULL;
}
else
{
//
// The mutex is taken. Add the calling task to the waiting list.
//
pCallingTask = os.pRunningTask;
pCallingTask->state = Waiting;
os.readyList.remove(pCallingTask);
waitingList.insert(pCallingTask);
os.schedule(); // Scheduling Point
// When the mutex is released, the caller begins executing here.
}
exitCS(); ////// Critical Section End
} /* take() */
The neatest thing about the take method is that if the mutex is currently held by another task (that is, the binary flag is already set), the calling task will be suspended until the mutex is released by that other task. This is kind of like telling your spouse that you are going to take a nap and asking him or her to wake you up when dinner is ready. It is even possible for multiple tasks to be waiting for the same mutex. In fact, the waiting list associated with each mutex is ordered by priority, so the highest-priority waiting task will always be awakened first.
The method that comes next is used to release a mutex. Although this method could be called by any task, it is expected that only a task that previously called take would invoke it. Unlike take, this routine will never block. However, one possible result of releasing the mutex could be to wake a task of higher priority. In that case, the releasing task would immediately be forced (by the scheduler) to give up control of the processor, in favor of the higher-priority task.
/**********************************************************************
*
* Method: release()
*
* Description: Release a mutex that is held by the calling task.
*
* Notes:
*
* Returns: None defined.
*
**********************************************************************/
void
Mutex::release(void)
{
Task * pWaitingTask;
enterCS(); ////// Critical Section Begins
if (state == Held)
{
pWaitingTask = waitingList.pTop;
if (pWaitingTask != NULL)
{
//
// Wake the first task on the waiting list.
//
waitingList.pTop = pWaitingTask->pNext;
pWaitingTask->state = Ready;
os.readyList.insert(pWaitingTask);
os.schedule(); // Scheduling Point
}
else
{
state = Available;
}
}
exitCS(); ////// Critical Section End
} /* release() */
The primary use of mutexes is for the protection of shared resources. Shared resources are global variables, memory buffers, or device registers that are accessed by multiple tasks. A mutex can be used to limit access to such a resource to one task at a time. It is like the stoplight that controls access to an intersection. Remember that in a multitasking environment you generally don't know in which order the tasks will be executed at runtime. One task might be writing some data into a memory buffer when it is suddenly interrupted by a higher-priority task. If the higher-priority task were to modify that same region of memory, then bad things could happen. At the very least, some of the lower-priority task's data would be overwritten.
Pieces of code that access shared resources contain critical sections. We've already seen something similar inside the operating system. There, we simply disabled interrupts during the critical section. But tasks cannot (wisely) disable interrupts. If they were allowed to do so, other tasks—even higher-priority tasks that didn't share the same resource—would not be able to execute during that interval. So we want and need a mechanism to protect critical sections within tasks without disabling interrupts. And mutexes provide that mechanism.
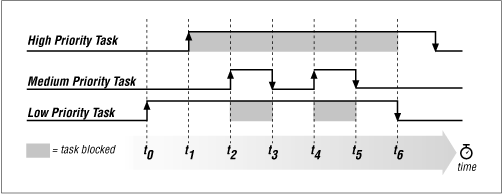
Deadlock and Priority InversionMutexes are powerful tools for synchronizing access to shared resources. However, they are not without their own dangers. Two of the most important problems to watch out for are deadlock and priority inversion. Deadlock can occur whenever there is a circular dependency between tasks and resources. The simplest example is that of two tasks, each of which require two mutexes: A and B. If one task takes mutex A and waits for mutex B while the other takes mutex B and waits for mutex A, then both tasks are waiting for an event that will never occur. This essentially brings both tasks to a halt and, though other tasks might continue to run for a while, could bring the entire system to a standstill eventually. The only way to end the deadlock is to reboot the entire system. Priority inversion occurs whenever a higher-priority task is blocked, waiting for a mutex that is held by a lower-priority task. This might not sound like too big a deal—after all, the mutex is just doing its job of arbitrating access to the shared resource—because the higher-priority task is written with the knowledge that sometimes the lower-priority task will be using the resource they share. However, consider what happens if there is a third task that has a priority somewhere between those two. This situation is illustrated in Figure 8-4. Here there are three tasks: high priority, medium priority, and low priority. Low becomes ready first (indicated by the rising edge) and, shortly thereafter, takes the mutex. Now, when high becomes ready, it must block (indicated by the shaded region) until low is done with their shared resource. The problem is that Medium, which does not even require access to that resource, gets to preempt Low and run even though it will delay High's use of the processor. Many solutions to this problem have been proposed, the most common of which is called "priority inheritance." This solution has Low's priority increased to that of High as soon as High begins waiting for the mutex. Some operating systems include this "fix" within their mutex implementation, but the majority do not. |
You've now learned everything there is to learn about one simple embedded operating system. Its basic elements are the scheduler and scheduling points, context switch routine, definition of a task, and a mechanism for intertask communication. Every useful embedded operating system will have these same elements. However, you don't always need to know how they are implemented. You can usually just treat the operating system as a black box on which you, as application programmer, rely. You simply write the code for each task and make calls to the operating system when and if necessary. The operating system will ensure that these tasks run at the appropriate times relative to one another.
Engineers often use the term real-time to describe computing problems for which a late answer is as bad as a wrong one. These problems are said to have deadlines, and embedded systems frequently operate under such constraints. For example, if the embedded software that controls your anti-lock brakes misses one of its deadlines, you might find yourself in an accident. (You might even be killed!) So it is extremely important that the designers of real-time embedded systems know everything they can about the behavior and performance of their hardware and software. In this section we will discuss the performance characteristics of real-time operating systems, which are a common component of real-time systems.
The designers of real-time systems spend a large amount of their time worrying about worst-case performance. They must constantly ask themselves questions like the following: What is the worst-case time between the human operator pressing the brake pedal and an interrupt signal arriving at the processor? What is the worst-case interrupt latency, the time between interrupt arrival and the start of the associated interrupt service routine (ISR)? And what is the worst-case time for the software to respond by triggering the braking mechanism? Average or expected-case analysis simply will not suffice in such systems.
Most of the commercial embedded operating systems available today are designed for possible inclusion in real-time systems. In the ideal case, this means that their worst-case performance is well understood and documented. To earn the distinctive title "Real-Time Operating System" (RTOS), an operating system should be deterministic and have guaranteed worst-case interrupt latency and context switch times. Given these characteristics and the relative priorities of the tasks and interrupts in your system, it is possible to analyze the worst-case performance of the software.
An operating system is said to be deterministic if the worst-case execution time of each of the system calls is calculable. An operating system vendor that takes the real-time behavior of its RTOS seriously will usually publish a data sheet that provides the minimum, average, and maximum number of clock cycles required by each system call. These numbers might be different for different processors, but it is reasonable to expect that if the algorithm is deterministic on one processor, it will be so on any other. (The actual times can differ.)
Interrupt latency is the total length of time from an interrupt signal's arrival at the processor to the start of the associated interrupt service routine. When an interrupt occurs, the processor must take several steps before executing the ISR. First, the processor must finish executing the current instruction. That probably takes less than one clock cycle, but some complex instructions require more time than that. Next, the interrupt type must be recognized. This is done by the processor hardware and does not slow or suspend the running task. Finally, and only if interrupts are enabled, the ISR that is associated with the interrupt is started.
Of course, if interrupts are ever disabled within the
operating system, the worst-case interrupt latency increases by the maximum
amount of time that they are turned off. But as we have just seen, there are
many places where interrupts are disabled. These are the critical sections we
talked about earlier, and there are no alternative methods for protecting them.
Each operating system will disable interrupts for a different length of time, so
it is important that you know what your system's requirements are. One real-time
project might require a guaranteed interrupt response time as short as 1
![]() s,
while another requires only 100
s,
while another requires only 100
![]() s.
s.
The third real-time characteristic of an operating system is
the amount of time required to perform a context switch. This is important
because it represents overhead across your entire system. For example, imagine
that the average execution time of any task before it blocks is 100
![]() s
but that the context switch time is also 100
s
but that the context switch time is also 100
![]() s.
In that case, fully one-half of the processor's time is spent within the context
switch routine! Again, there is no magic number and the actual times are usually
processor-specific because they are dependent on the number of registers that
must be saved and where. Be sure to get these numbers from any operating system
vendor you are thinking of using. That way, there won't be any last-minute
surprises.
s.
In that case, fully one-half of the processor's time is spent within the context
switch routine! Again, there is no magic number and the actual times are usually
processor-specific because they are dependent on the number of registers that
must be saved and where. Be sure to get these numbers from any operating system
vendor you are thinking of using. That way, there won't be any last-minute
surprises.
Despite my earlier statement about how easy it is to write your own operating system, I still strongly recommend buying one if you can afford to. Let me say that again: I highly recommend buying a commercial operating system, rather than writing your own. I know of several good operating systems that can be obtained for just a few thousand dollars. Considering the cost of engineering time these days, that's a bargain by almost any measure. In fact, a wide variety of operating systems are available to suit most projects and pocketbooks. In this section we will discuss the process of selecting the commercial operating system that best fits the needs of your project.
Commercial operating systems form a continuum of functionality, performance, and price. Those at the lower end of the spectrum offer only a basic scheduler and a few other system calls. These operating systems are usually inexpensive, come with source code that you can modify, and do not require payment of royalties. Accelerated Technology's Nucleus and Kadak's AMX both fall into this category,[2] as do any of the embedded versions of DOS.
Operating systems at the other end of the spectrum typically include a lot of useful functionality beyond just the scheduler. They might also make stronger (or better) guarantees about real-time performance. These operating systems can be quite expensive, though, with startup costs ranging from $10,000 to $50,000 and royalties due on every copy shipped in ROM. However, this price often includes free technical support and training and a set of integrated development tools. Examples are Wind River Systems' VxWorks, Integrated Systems' pSOS, and Microtec's VRTX. These are three of the most popular real-time operating systems on the market.
Between these two extremes are the operating systems that have a bit more functionality than just the basic scheduler and make some reasonable guarantees about their real-time performance. While the up-front costs and royalties are reasonable, these operating systems usually do not include source code, and technical support might cost extra. This is the category for most of the commercial operating systems not mentioned earlier.
With such a wide variety of operating systems and features to choose from, it can be difficult to decide which is the best for your project. Try putting your processor, real-time performance, and budgetary requirements first. These are criteria that you cannot change, so you can use them to narrow the possible choices to a dozen or fewer products. Then contact all of the vendors of the remaining operating systems for more detailed technical information.
At this point, many people make their decision based on compatibility with existing cross-compilers, debuggers, and other development tools. But it's really up to you to decide what additional features are most important for your project. No matter what you decide to buy, the basic kernel will be about the same as the one described in this chapter. The differences will most likely be measured in processors supported, minimum and maximum memory requirements, availability of add-on software modules (networking protocol stacks, device drivers, and Flash filesystems are common examples), and compatibility with third-party development tools.
Remember that the best reason to choose a commercial operating system is the advantage of using something that is better tested and, therefore, more reliable than a kernel you have developed internally (or obtained for free out of a book). So one of the most important things you should be looking for from your OS vendor is experience. And if your system demands real-time performance, you will definitely want to go with an operating system that has been used successfully in lots of real-time systems. For example, find out which operating system NASA used for its most recent mission. I'd be willing to bet it's a good one.
[1] Remember, task creation is one of our scheduling points. If the scheduler has been started, there is also a possibility that the new task will be the highest priority ready task.
[2] Please don't write to complain. I'm not maligning either of these operating systems. In fact, from what I know of both, I would highly recommend them as high-quality, low-cost commercial solutions.